为了深入落实国家大数据战略,推动大数据产业交流与合作,展示我国大数据产业最新发展成果,2019年6月4日至5日,由中国信息通信研究院、中国通信标准化协会主办、大数据技术标准推进委员会承办的2019大数据产业峰会在北京国际会议中心隆重举办。
会上,来自工业和信息化部的领导,我国众多优秀大数据领域服务商、行业应用客户、研究机构、地方大数据主管机构的领导和专家,将对大数据政策、产业、技术的现状与趋势等内容进行交流探讨。
6月5日,在大数据前沿技术分论坛上,百度资深研发工程师陈凯为我们带来了主题为《基于异构计算的数据科学加速方案》的演讲。

大家好,我是陈凯,来自百度,是百度资深软件工程师。今天演讲的主题是《基于异构计算的数据科学加速方案》。
从数据科学现状讲起,以今年非常火的4月10日首次通过设定望远镜发现黑洞来说明。我们通过地球上的八台大口径射电望远镜发现黑洞,处女座星系离地球非常远大概五千多万光年,单靠肉眼无法看见它,当然黑洞是看不见的,肉眼是不可见的,与此同时它会吸收可见光,对一般的科学仪器也是不可见的。通过这样一个数据最终看到黑洞就是一个典型的数据科学的过程。在这些数据科学的过程里面包括李总前面提到联通有非常大量的数据,在这个地方也是海量的数据。基于海量的数据如何看到这样一个黑洞,就引出下面的过程。
数据科学就是从刚才的比如通过射电望远镜的观测数据最终发现黑洞的过程,数据科学的定义是利用数据学习知识,我们发现黑洞验证爱因斯坦的广义相对论在极端环境下依然是成立的。数据科学涵盖了非常多的交叉学科——应用数学、统计、模式识别、机器学习、深度学习……还需要高性能计算的支持。与此同时,包括黑洞本质上来讲是无法看到的,我们最终通过一种可视化的方法把射电望远镜处理的数据进行可视化,总体是这样的过程。
它的核心技术体系,首先数据是第一要素。我们通过观测到数据做数据分析,数据分析传统在两千多年前,最早用算盘加上珠算口诀表,今天这样的算力是不够用了,所以今天有一些专门的支持。在今天CPU是典型的计算硬件,作为通用的处理器可以做很多计算。在算法方面,通过比如包括数据预处理、数据分析、数据可视化来完成整个流程。
刚才所描述的是数据科学的背景,接下来描述数据科学的技术现状,从两部分进行讲起。
1、数据科学目前算力的情况。除了通用/常用的CPU,通用处理器之外,在大家机器上通常有图像显示卡,今天已经超过图像显示卡的范畴,已经应用于高性能计算,我们讲一下图像显示卡跟CPU技术的区别。
图像显示卡会简化逻辑控制单元,比如汇编,每一套指令的执行首先来讲需要取子、取操作数进行计算。一般结构分两部分,第一是怎么样在里面计算,第二是怎么从里面抽数据。比如CPU单指令流单数据流,在显示卡里是多指令流多数据流这样的逻辑控制单元。简化了单元之后,第二部分简化在cache级方法。CPU作为一种通用性的硬件需要考虑,怎么加速程序的执行,GPU里是不需要的,这两个控制结构比较简单,与此同时有足够多的空间,比如做流处理器,像我们经常提到的超限的概念,有很多ALU这样的计算单元。常用CPU里面只有10%不到的空间,但是GPU里面有将近40%的空间做计算单元。
按照这样的体系,第一是怎么算的更快,应该由外部输入这些数据。从数据来看主体数据是存在内存里的,在CPU和GPU内存来看,GPU把一大部分内存嵌入上去,使用的概率比CPU高,它的内存带宽是CPU的一到两个数量级,百度云上的数据大概是38倍的关系。所以GPU本质上来讲非常适合做高性能计算,包括今天世界500强的排名比较考前的高性能计算的机器里面,主体是CPU和GPU耦合的模式。这里有组数据显示,民用用的比较多的,像英伟达的LTX——民用显卡性能超过了最顶级的铂金版8系和9系的处理。因为GPU结构上相对简单,功耗上相对小一些,不仅有性能优势还有成本的优势。
除了GPU,今天我们看到的不仅仅是GPU,还有其他高性能计算硬件。作为FPC的老大,谷歌06年开始在数据卡上支持数据科学,也开始推出TPU1.0,今天已经是3.0的模式了。如图这些都是在服务器端经常能用到的。民用的主要是手机上,华为的mate20、P30这样的手执设备也用了高性能计算硬件。这里描述了4个算法的支持,TPU为例,单位功耗性能比CPU高196倍,比GPU高68倍,这是各个算力的你追我赶,毫不示弱。
2、接下来谈一下算法维度。不知道今天在场有多少朋友是做机器学习或者数据科学的,大概用到哪些常用的算法。Scikit-learn或者深度学习的框架,大家可以举一下手,还挺多的。我们这里有个统计,选取一些全球的消费者做了一些数据。图中显示,在数据科学里面经常用到一些算法,包括分类、聚类等等,这里面非常火的像深度学习、卷集神经网络,这里可能没有完全拔得头筹,说明传统的机器学习还是大有用武之地的。
头部来讲,传统的机器学习数据分析主要是这样一些,在机器学习方面,传统的Scikit-learn,2008年左右开始涌现了这样一款软件,到今天为止它的生命力依然非常旺盛。还有一些后起之秀,比如做XGboost还有高性能模式。这里有一些Scikit-learn支持的算法列表,可以看一下Scikit-learn是个非常好的对应到算法上,当大家有了数据分析的需求或者还拿不定用什么样的算法的时候可能会优先选择Scikit-learn做尝试。
Scikit-learn所支持的算法非常广泛之外,另外一个,Scikit-learn有个非常好的代码接口的应用性和代码维护性。他们官方自认为他们所追求的第一要素是接口应用和整体代码维护性,我们以SVM解决经典易获的数据,以建模为例,如图这是易获的数据,通过经典的分类方式难以解决,我们以Scikit-learn解决,描述一下数据过程,先有数据做预处理,与此同时调用一个模型,调用模型的pd方法,相当于构建了这样一个模型,接下来用predict方法截取应用层模型做相关的预测,实际上Scikit-learn在易用性的同时也存在一些性能上的问题,特别是刚才李总描述的,数据越来越大,用Scikit-learn往往我们只能用于处理一些相对来说不那么多的数据,Scikit-learn要支持更大量的数据就会存在一些性能上的瓶颈。这时候Scikit-learn自己官方也给出来一个建议的优化步骤,总体而言是具体问题具体分析,大概是如下几个步骤:1、寻找瓶颈,这个相对容易;2、重写代码,Scikit-learn自己推定的方法,比如对接口的分装,需要写代码,用一些高性能语言重写这部分代码;3、对比测试,比如有并行优化过程,第二步还是相对比较复杂的。前面也提到了优化,Scikit-learn在可预见的将来应该是不会支持GPU,支持GPU影响代码的可读性和兼容性,所以其他的设备更不用说了,我们可以看到3W 2018年有篇论文描述,GPU对SVM加速效果,高加速81倍,当然在Scikit-learn里是产生不到的。
前面我们描述了算力和算法当前的现状,总结一下因为算法实际上是面对终端用户的,可以看一下整个这套体系里目前存在的问题,比如以Scikit-learn为例,接口抽象性非常好、简单易用,易用可读性相对比较好,代码可维护性非常强。但是相应的不足主要是计算性能不独,性能优化给了一些建议,相对比较复杂,有时候往往需要重新写代码。另外一点是在今天数据越来越大,成本也是我们不可忽视的环节,Scikit-learn总体的研发跑的慢,跑的多,资源成本高一些。基于异构计算整个加速分如下三层:1、加速,算法和算力协同工作,算法支持更高效的算力。2、降本,怎么样更好的利用整个资源。3、吸取Scikit-learn在推广方面的优势,异用性,通过原先的接口降低用户整体的迁移成本,提供更易用的接口。
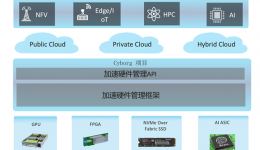
接下来讨论一下整体描述方案。1、加速部分的工作;算法协同算力提升数据科学性能要应用高性能的异构算力。异构算力更快更省,在性能成本两方面的优势,在上层算法上适配,支持各种不同的模型,包括常用的数据分析的类似于现在用的比较多的,另外是图分析,传统的像单元里最短路径或者是图上的算法,以及应用比较多的图嵌入、图传播这样的算法。机器学习也是我们大力支持的,最后一块是深度学习,深度学习大家知道现在有非常多的库,像Paddle已经是非常好的了,但是这只是在这一个环节,但是如果需要数据分析时怎么处理,有比较多的数据的互拷贝和格式的转换。但是CPU里面数据拷贝是无关紧要的,当涉及到外设,像FPGA也是一种外设,需要把数据拷贝到外设上,拷贝过程比较费时,所以在下层有个统一的数据格式来减少数据拷贝,让大家使用同样格式的数据降低数据拷贝的时延。另外我们也为简单,有资源管理层接口屏蔽资源差异。
前面描述的主要是加速的工作,让算法适配算力,与此同时为了让各个算法之间做到无缝,是需要每个步骤都执行比较快,同时每个过程之间转换的开销相当于最优,前面是解决这个问题。
接下来要解决省资源的政策,优化成本的工作。前面提到了基于异构计算,本质上来讲更省成本,因为异构及乱本质上来讲跑的会更快,资源本身成本更优,同时做异构计算过程中也会有一些资源上的浪费,这个过程是解决资源浪费的问题,以今天比较常见的GPU为例来进行说明,我们知道GPU作为一个外设,它本质上跟打印机比较类似,在某个时间窗口独享资源,比如这时候有多个进程同时复用一张显卡这时候往往是比较慢的,我们可以看到一个时间轴上,分别执行路径,在一个时间点上执行路径,在这个过程中只占用了50%的资源,我们知道对于GPU里会有数千个核心,意味着也有数千个核心浪费了,我们这个地方通过一个资源更优化的管控来做到资源的最优化利用,降低整个资源成本。右图是实施的方法,这个过程中可以看到,在同一个时间片,刚才描述的是时间轴,右图是时间片上的过程,一个时间片上三个用户同时提交三个作业,三个作业可以在同一个时间片里面很好的复用一个计算单元,计算单元在这里比较好的复用,通过这种方式在异构计算的基础上进一步降低整个计算成本。
在提供这样的接口降低成本的同时也需要兼顾用户的改造,我们是兼容用户的接口,降低用户迁移成本,还是前面描述的通过Scikit-learnXOM解决异构,过程中只需要改变库就可以应用刚才所描述的加速方案。
与此同时我们通过AutoML提供更易用的接口,更有利于异构计算的推广。首先通过AutoML提供更易用的接口,用户在上面提供任务,通过建议器和评估器给用户一些路径,让用户尽量少的尝试。这样少的尝试都通过AutoML底层服务完成,最后希望给用户非常好的结果。通过异构计算又加快了整个AutoML迭代的过程。除此之外异构计算加速AutoML也有其他的点,包括特征工程的优化,像前面所描述的,加速整个数据预处理的过程。加快整个评估优化,通过CUML加速整个结果的优化。与此同时做到全流程自动化,让用户可以更好的,甚至是他自己定义的算法放进去支持AutoML。
前面我们描述了在加速机器学习上省成本和接口上的相关工作,接下来描述一下应用案例。付院长也分析过大数据场景,这里也是这样的场景,目标是位置分类,针对卫星地图给某个位置定义一个标签。大家可能会问,地图里面本身就有这些数据,比如POI或者AI,过程更精细有KOI的数据,为什么不直接用呢?有很多大型的机构往往比较大,有很多学生,比如清华大学里面会含有医院这样的实体,与此同时还有中小学这样一些实体都是放在清华大学里面的,我们希望通过这样的分类更好的把这些实体完全区分开来,这是我们的背景。
接下来把它映射到解决方案中去,跟图形截取类似,首先第一步搜索这样的数据,第二是对这些数据做一些处理的过程,接下来对数据做了一些处理,提取一些特征,接下来做特征相关的融合,最后基于特征做这样的分类,大概是这样的过程。这个过程中发现,图嵌入的会比较慢,往往数小时才能完成这样的工作,我们基于前面所描述的系统对这部分工作进行加速。大家知道图嵌入本质上讲是把高维析出的空间嵌入到低维空间里去,比如128维的空间,不是特别好的直观看到的数据进一步嵌入二维平面上去,如图对应的点就是一个实体,在这个平面上点越近表示图嵌入效果越好,大家看到这是一些大学实体,最终向量聚焦于这一块,我们对它做了相对比较好的分类。
把刚才的图映射到卫星地图上看,我们发现对于清华大学的附中做比较好的区分,清华大学附中从清华大学剥离出来,把这一块作为中小学的实体,满足这样功能的同时,整体训练过程平均加速13倍,与此同时整个成本降至12%,有非常好的加速效果。
下面是我们通过异构计算加速数据科学的方案,整个产品落地于百度云数据科学平台这样一个产品上,大家可以通过这个产品看到,是个编程的界面,与此同时在里面内置了自动机器学习以及下层加速好的算子。有类似于题词器这样的概念,大家想做哪个功能可以更方便的应用到这些功能,上面还提供一些模型,大家比较好的复用我们之前的成果。产品主要的性能除了高性能、自动化、按需托管之外,另外是数据的安全和高效联合建模,让数据有更好的价值,通过数据共享发挥整个数据的价值,在共享过程中数据是可用但是不可见的。我们数据科学平台的入口网址如图,欢迎大家去试用。