







今天,对大数据的分析挖掘已经成为企业提升竞争力的全新支点。各行各业在大数据领域的商业进程明显加速,但如何让大数据发挥价值还面临很多困境。
除了数据的使用权、数据安全、数据存储等问题,现阶段,更多的人对大数据技术本身能够开发出什么样的产品,提供什么样的服务更感兴趣。
因此,UCloud特地在杭州举办了UCan下午茶活动,聚焦数据价值,探讨如何在技术层面进行数据安全实践,为数据商业化变现探寻新出路。

现场座无虚席,UCloud存储研发工程师丁顺首先带来了主题为「数据库高可用容灾方案设计和实现」的分享。

高可用数据库,即一系列数据库构成的集群。它通常的架构是有一个主节点来处理主要请求,另一个备用节点作为容灾切换使用,当主节点不能提供服务的时候,备节点可以成为主节点继续提供服务,从而保证整个系统的可用和稳定。
因此,使用高可用数据库的好处也非常明显。丁顺表示,「一是系统可用性提高;二是可以方便的读写分离。即操作中可以在主数据库节点上进行,吞吐量明显多于单个数据库;三是变更不停服,它是指做变更时可以先升级备节点,再做主层切换,升级后的备节点变成主节点,再把之前主节点再做升级,对用户影响非常小;四是备份不影响服务性能,因为有很多备节点可以做数据备份,所以主节点的性能不会受影响。」
因为高可用数据库的优势,业界有很多成熟的架构设计。而数据库主从复制是较经典的数据同步模式,它可以延伸出很多架构改进。现在UCloud的云数据库产品UDB就采取这种方案,那为什么要基于数据库的主从复制来做产品?
这是一个综合考虑的结果。丁顺表示,一方面是因为UDB的初衷即是在高可用架构中尽量基于原生MySQL,以涵盖不同的MySQL数据版本;二是在不同场景及存储引擎背景下,主从复制方案优势明显。
但高可用数据库也有非常大的痛点,那就是自动化运维。
而目前采用集中式管理方法的UDB采用自研的容灾模块,可以处理大规模、高并发的DB自动化容灾。除了自动化容灾之外,后台DB的运维体系还可以做到自动化问题探测以及问题修复,降低运维的难度和压力。
丁顺总结,这是因为UDB在运维当中的三个特性:一是日常做例行巡检,能够保证高可用数据库的健康;二是定期的容灾演练;三是高可用切换需要记录日志,在切换失败的时候需要做告警。这些能力能够让UDB能够达到良好的自动化运维效果。
分享过后,与会者还针对MySQL数据主从同步异常的问题进行了分析和探讨。
第二位进行主题演讲的嘉宾是UCloud资深数据库研发工程师刘坚君。他的分享题目是「新一代公有云分布式数据库——UCloud Exodus」。他认为,在公有云数据库1.0的基础上,云数据库2.0重新思考了用户需求痛点,基于公有云的进化能力创造出了全新价值,而UCloud Exodus将会是云数据库2.0时代的重要产品,现场他对其能力进行了详细的介绍。

刘坚君首先从1.0时代存在的问题入手,他认为1.0时代云数据库带来了三方面价值:弹性、故障救援、知识复用。但它同样有三个难以解决的问题:容量和性能、租用成本、运营成本。
到2.0时代,解决上述三个问题的思路是计算和读写分离。通过计算和读写分离,将传统数据库的计算层和存储层拆开,各自独立扩展和演进。带来的好处是:一是提供更大的容量和读写性能;二是按需扩容和付费;三是优化运营成本并降低运营风险。从而让1.0云数据库的三大问题可迎刃而解。
放眼来看,业界已推出的2.0云数据库(如Aurora、PolarDB等)均采用计算和存储分离的架构。而UCloud Exodus的产品和技术理念则更进一步:计算和存储分离后,存储层将完全复用云平台的高性能分布式存储(如UCloud UDisk、阿里云盘古等),而Exodus则专注于构建一款数据库内核,去适配主流公有云和私有云厂商发布的高性能分布式存储产品。Exodus的这种产品架构,称之为Shared-ALL-DISK架构。
Shared-ALL-DISK架构的优点明显。在提供云数据库2.0创新功能的同时,赋予了用户业务自由迁徙的能力,不被某个云平台绑架;同时能够连接上下游的软硬件厂商,共享云数据库2.0技术红利,共建Exodus数据库生态。中立、自由连接和利益共享,是UCloud成立以来一直强调的价值观。
更为重要的是Exodus最终开源,它会将核心系统的每一行源码开放,赋予用户深入了解和优化Exodus的能力;赋予同行改进,优化的自由。并建设开源社区,吸收全行业的优化成果,共同改进和完善Exodus。最终,UCloud Exodus将成为时间的朋友、用户的朋友、行业的朋友。
演讲中,刘坚君进一步阐述了三个朋友的概念。他指出,最近几年,某些公有云厂商和产品有成为下一代IOE的趋势,通过降价打压竞争对手和吸引用户,在产品上对用户业务的捆绑越发深入,导致敌人越多,朋友越少,长远来看不利于行业健康发展。而UCloud Exodus的目标,是希望成为云数据库平台中的MySQL。数据库系统,历来是IT行业的协作枢纽,UCloud希望打造一款开源的云数据库2.0产品,来重构云数据库格局乃至公有云格局,通过开放共享,用自由连接的方法让敌人越来越少,朋友越来越多,形成通过技术和服务,而不是品牌宣传和降价来相互竞争的格局,推动云计算健康发展。
当然,采用Shared-ALL-DISK这种开放式架构,有更多技术问题需要解决。其中的核心问题是IO路径问题,这也是计算和存分离架构中的根本问题。刘坚君认为,分析近几年的技术趋势,未来主流云平台上的分布式存储产品,必将朝高性能方向演进,最终在IO能力上足够承载数据库等高性能应用。
因此,应该有前瞻性地把IO路径问题的主战场,交给队友,交给云平台的分布式存储产品和团队。比如UCloud UDisk,以UCloud UDisk正在开发的新版本产品为例,现在已经测得了100us的IO延迟,100w+的IOPS。相信随着时间的推移,技术优化将不断深入,底层软硬件将不断升级,最终云平台的跨节点IO能力将达到非常高的水平。
但这并不意味着UCloud Exodus在IO路径上毫不作为。相反,Exodus将以MySQL为原型,对IO路径问题做大量优化。包括去除Binlog、去除内部二次提交、消除DoubleWrite等。这些技术手段的采用,将保证Exodus在高性能分布式存储之上,IO跑的又轻又快。
除了IO路径问题,另一个重要的技术问题是主从同步问题。在借鉴业内主流的Redolog同步思路的基础上,Exodus基于MySQL内部机制又做了创新。该创新方法提供了一种实现简单又运行高效的主从Redolog同步机制。
一套完整UCloud Exodus数据库系统,由Master、SLAVES、Binloger、分布式存储与对象存储构成。Master实例负责数据读写并同步redolog到Slaves;Slaves由一个或多个只读节点构成,缓存和主节点保持一致并向上提供只读能力;分布式存储负责数据的持久化存储,同时将数据页和redolog实时备份和归档到对象存储;而Binloger模块将根据对象存储中的归档redolog重演binlog,以向下游系统(如kafka等)提供binlog数据。
该系统预计2019年第三季度推出公测版,2020年一季度正式发布。
第三位的演讲嘉宾是来自网易的资深数据库内核及大数据技术专家蒋鸿翔,他带来了「基于Impala平台打造交互查询系统」为主题的分享。

交互查询是偏分析的方向。它的特点是数据量基数庞大,关系模型相对较复杂,响应时间要求较高。
因此,选择匹配的平台上,一般基于三个方面来考虑:一是本身项目熟悉度;二中大厂背书;三是性能和优缺点指标。
蒋鸿翔表示,现在业内有Impala交互查询平台,Facebook做的查询平台Presto,以及Green Plum。那如何去选?因为交互查询的数据是从大数据平台上来的,所以一般会考虑与Hadoop/Hive的兼容,社区环境及架构设计等因素。
之所以选择Impala平台,在于它的综合优势,主要体现在六个维度:第一,MPP架构;第二,执行节点无状态、去中心化;第三,兼容Hive存储;第四,Apache顶级项目、成熟社区;第五,多种数据格式兼容;第六,高效查询性能。
当然,Impala还有缺陷。包括服务单点、Web信息不持久化、资源隔离不精准、底层存储不能区分用户、负载均衡需要外部支持这几个方面。
针对这些缺点已经出台了不少改进方案。目前主要有基于ZK的Loadbalance,管理服务器,细粒度权限和代理,Json格式,兼容Ranger权限管理,批量元数据刷新,元数据同步和过滤等维度。
其实,Impala平台的应用场景也非常多。基于用户数据沉淀,做不同形式的预测和推荐,从而大化利用数据。
随后,UCloud技术专家王仆带来了主题演讲「UCloud分布式KV存储系统」。
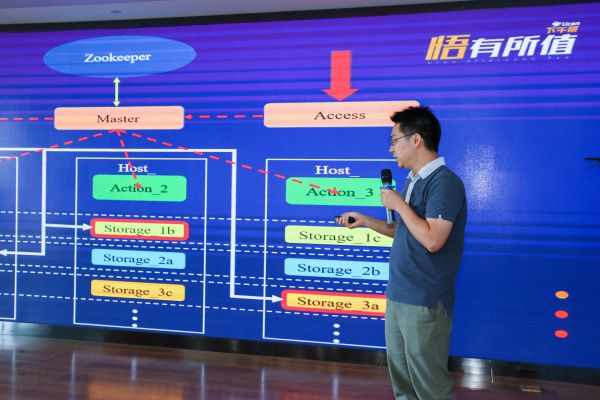
在线服务Redis是当前比较流行的协议,它支持比较多的数据结构。可以被用于内存缓存、持久化存储等不同场景,大量服务于各类互联网应用。
同时也提供了丰富的功能配置,客户可以根据各自业务需求,在读写性能、缓存容量、数据可靠性等方面作出灵活的选择。
Redis是主要有三个优势,一是拥有超高性能,读写性能可达10万以上;二是支持string、list、hash、set、sorted set等丰富的数据结构;三是支持排序、集合类运算、位运算、过期淘汰等复杂运算。
目前已经有很多企业都在使用Redis产品。比如说大型社交APP的客户。通常,社交的APP在Server端比较简单,会存储一些用户信息,包括发布信息的状态、关注、消息发布等。这些庞大的信息运转就需要快速的处理,而使用Redis的数据结构来缓存数据,能够实现较快的响应。
活动接近尾声,杭州钱塘江已经被一片金色笼罩,但与会者依然热情,非常积极踊跃地参与交流互动。最后一位演讲来自于华为的技术专家时金魁,他带来了「实时流计算技术及其应用」的主题分享。
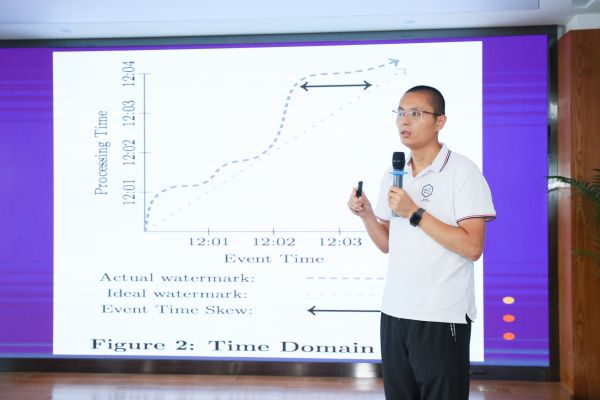
实时流在这两年比较流行,而它的基础就是大数据。目前,实时云计算适用场景比较多,包括广告、监控大盘、打车软件、金融风控、异常检测、交通、物流、外卖等等。
比如,在打车场景中,一般会在APP中会显示预计费用,显示费用通过实时预测出来,而不是真正发生的计价,这就是实时流日常运用的场景之一。
今天较出众的实时流计算框架是Flink。
Flink除了有TABLE,还能够做一些SQL。目前在Flink上面可以做时空数据,主要用在物联网方向,比如说车联网、物联网,还有一些基于曲线,比较典型的是电子围栏、车辆超速等等。除此之外,还有地理位置、智能学习模型、实时推理。因为数据是实时流进来的,可以做实时推理并且应用到业务系统。
时金魁还提到,现在的潮流是流计算双引擎:Flink+Spark,这个非常有用。它可以实现很多,比如Stream SQL表达,在线机器学习,实时故障检测等等。如果一些数据指标出现异常会训练,它是否异常可以通过实时流发现,一旦发现做一些归类,如果是异常情况实时做告警,还有驾驶员分析等等。
活动最后,意犹未尽的开发者们还与演讲嘉宾们就一些话题进行了交流。而大数据技术的探讨之后,UCan下午茶还将走进深圳等地,继续对技术趋势进行火热探讨和交流,敬请关注后续系列活动。






















