







经过前文对数据存储的介绍,大家对RapidsDB的数据存储方面有了一定的认知。同时朋友们可能也会思考,作为新一代的分布式数据库,RapidsDB还有没有更硬核的优化手段?抠细节能抠出个三室一厅那种?
好!!本文我们就RapidsDB数据编码方面来看如何做到性能加速。
介绍RapidsDB的数据编码,准确地说,是介绍存在磁盘内的列存储表的数据编码。列存储表的数据以多种不同形式编码存储,包括字典编码、游程编码和值编码。只有某些编码可以直接处理,即直接“操作”,如字典编码、游程编码和整数值编码。
以字典编码为例,对于只有3个不同值的字符串列的一个段,为每个字符串存储一个2位的ID号,ID号被用作字典的参考。当存储在列存储中时,这些ID被紧紧地打包在一起。请参考以下字典:

当它被存储到列段中时,可以表示为打包字符串ID的位向量:
lStrings:”red”,”blue”,”green”,”green”,”red”
lStrings IDs:0,2,1,1,0
lBit vector:00 10 01 01 00 (2 bits per string ID)
作为直接对编码数据进行操作的例子,RapidsDB可以对字符串字典编码的列段执行过滤操作,比如说“t.a=’xyz’”,方法是首先找到字典中每个条目的过滤结果,然后在扫描该段时,查询执行系统简单地获取t.a中每个值的编码ID号,并使用它来查找在字典的初始扫描中计算的该ID的字符串比较结果。这往往比实际情况中的字符串比较要快得多。其他类型的操作也可以直接在编码数据ID值上完成,包括比较进行分组操作所需的ID值。更多细节可自行拓展了解。
在列存储扫描之外的RapidsDB中的大多数查询处理都是一次一行地完成的。对编码数据的列存储处理以矢量化的方式完成,其中来自一列的大批量数据在一个或多个相对简单的循环中处理。与一次一行的处理相比,这些循环对现在CPU更加友好,通过降低指令数量,提高了高速缓存使用率,并提高了处理器指令流水线的效率。
基于上述编码,通过使用特殊的编码处理技术以及支持英特尔AVX2指令集的处理器上的单指令多数据(SIMD)指令,使包括过滤和聚合在内的某些操作可以在非常高效的状态下运行。
硬件上的SIMD不是编码数据优化的唯一核心,即使没有SIMD的支持,对编码数据的操作性能也会提高几倍到30倍;使用了SIMD则可以进一步提升性能,带来至少2-3倍的增益。具体优化结果将取决于数据及查询。个别查询的一些部分可能不需要对编码数据进行操作,因此用户体验到的加速效果可能会有所不同。
默认情况下,对数据编码的操作是数据库内部自动执行的。用户不需要更改任何设置就能从中受益。对数据编码使用操作是查询在系统运行时生成的,而不是由查询优化器做出的。
编码数据的查询优化只能在列式表中体现,需要具备以下一个或多个组件:
l过滤器Filters
l分组 Group by
l聚合 Aggregates
l聚合表达式
l分组表达式
l整数列上的Star joins
不管运行中的编码列不同值的数量是多少,都可以对编码数据进行优化操作。编码中不同值的数量越少,优化性能越好。这是因为当字典变小时,意味着列存储数据被压缩到更小的尺寸,进而查找表过程中更容易适配到处理器的高速缓存。
先举个查询例子,它通过使用了几个包含性能优化的组件从而在对编码数据的操作中提升了性能:
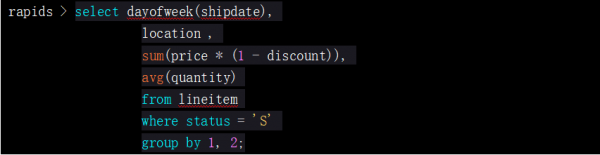
如果再加上一张列式表f,也可以从编码数据的连接操作中得到性能优化。查询示例:
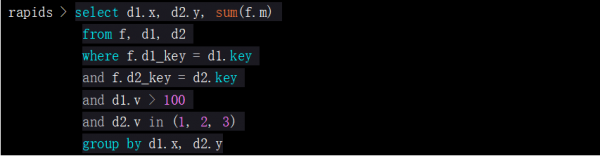
这个查询是星型模型Star joins的一个简单例子。如果用户使用星型模型Star joins做关联,并且关联键是整数类型,那么查询就可以在编码数据的操作中得到性能优化。简单说明,这里是使用group by子句和聚合函数从编码数据的连接操作中加速性能。
l再举个表关联的例子:
这个例子展示了编码连接的作用: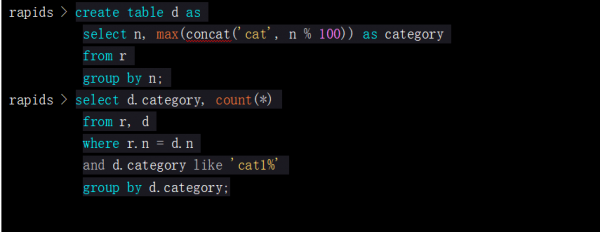
后面的关联查询在双核笔记本电脑上,只需要0.02秒算出结果。注意了,它是对表r做一百万行的全表扫描,然后与维表d(110行)做连接。
通过查看RapidsDB的图形计划或者show profile json的结果输出,可以了解数据编码功能连接正被用于上述语句配置文件的查询计划中:在HashJoin运算符上,可以看到属性"encoded_join_enabled":"yes"。此外,还可以看到对编码数据的操作被推送到ColumnStoreScan列存扫描运算符。ColumnStoreScan、 HashJoin和各种GroupBy运算符可以在扫描过程中通过一个或多个散列连接(hash joins)的序列来共同实现星型连接(star join)。
ü支持的编码数据
目前RapidsDB仅对以下情况支持对编码数据的操作:
l带有字符串字典和字符串游程编码的字符串类型;
l具有值和行程编码的整数列。
分组、聚合操作仅支持整数类型做数据编码。过滤支持字符串和整数类型做编码数据。
通常RapidsDB会自动对列存储数据进行编码。但是,在极少数情况下,本该自动编码的操作没有被编码数据识别到,但对用户的应用程序来说,这次数据编码优化十分重要,则可以通过option '<encoding>'符号来实现,例如:

ü支持的操作和限制
对编码数据支持的操作以及对操作的限制做个详细分类说明:
n扫描Scan:
l整数编码更快解码
n过滤Filter:
l下列过滤器:
u字符串字典和字符串游程编码的字符串类型
u用于游程编码的整数类型
l过滤器表达式中的“或”运算;筛选器表达式必须包含单个字符串列,以加快处理速度
l支持字符串列上的Bloom筛选器(消除单个字符串列上没有匹配连接的行)
n聚合Aggregates:
l支持的聚合:sum, min, max, count, any
l支持的聚合数据类型:全数字
l支持的聚合表达式:一个表达式中允许有多个表列
l支持的聚合编码:整数、整数游程编码
n分组Group-by
l没有分组的聚合(也称为标量聚合)不会对编码数据执行操作
l分组计数启动非常快
l分组:
u允许有多个分组列
u允许混合使用列和表达式
u分组列必须仅使用以下编码:整数、整数游程编码
u每列几千行不同值的数量有一个限制,超过这个限制,系统将恢复到一次一行的处理,并且行段的数据的本地聚合将向父全局聚合运算符输出行
u类似的,对几千个组的组总数也有一个限制,超过这个限制就不使用优化的分组处理
u排序关键字上的分组可能不如其他列上的分组高效,因为可以执行有序分组,而哈希分组可能更好
l分组的表达式:
u一个表达式中只允许一个输入列
u表达式结果必须为整数
u在分组列和表达式集中,每个列表只能使用一次
n关联Joins
l连接必须在某种类型的整数列上,或者在内部表示为整数的另一种列类型上,如datetime
l查询优化器选择的一个或多个连接必须是HashJoin类型
l连接必须是多对一的关系
lHashJoin(或一些列HashJoin)必须出现在上 ColumnStoreScan
l对连接结果的查询中必须存在按操作分组和聚合
柏睿数据RapidsDB在某国有大行普惠金融项目应用中,对应用开发人员进行了开发优化建议和几次针对性查询优化中,就使用了数据编码的方法,取得了明显的效果:优化前后得到5-20倍的效果。
好了,数据编码我们介绍到这。如果您有疑问或建议,欢迎在后台留言,我们将针对大家的共性问题,发布【答疑篇】,互动的同学有机会获得神秘奖品呦。
RapidsDB极限性能数据库有何妙处?第二回将开启“高性能篇—行列混存”解读。欢迎关注“柏睿数据”公众号,继续修炼数据库~
















